Поговорим о приёмах, которые я всегда называл «подменой задачи», поскольку вместо исходной задачи машинного обучения здесь решается другая задача (с модифицированными данными и другим целевым вектором) с целью анализа данных и улучшения качества решения исходной задачи. В западных источниках некоторые описанные приёмы называются специальными терминами, например, Adversarial Validation, но на русский они всё равно плохо переводятся, поэтому, как я называю с 2010 года – «подмена задачи». Для понимания материала нужно знать постановку задачи машинного обучения и основные термины.

Исходная задача
Пусть у нас есть исходная задача классификации / регрессии, которая символично изображена на рис. 1. Всё традиционно: объекты заданы признаковым описанием, для определённости на рис. 1 показан бинарный целевой вектор – разные целевые метки изображены красным и синим. На объектах тестовой выборки «test» во время обучения модели значения целевого признака не известны.

Проверка зависимостей признаков
Один из важнейших этапов подготовки данных – сокращение числа признаков для устранения избыточной информации. Простейшие методы фильтрации позволяют выявлять лишь простые зависимости, например линейные. Если какой-то выбранный признак сделать целевым и попытаться настроить модель восстановления этого признака по значениям других, то успех в этой попытке означает, что выбранный признак зависит (функционально) от других. Если модель имеет встроенные механизмы оценки важности признаков, то можно понять, от каких признаков зависит выбранный. Более того, выбор модели позволяет искать определённые зависимости. Например,
- линейная регрессия – линейные,
- обобщённая линейная – полиномиальные и т.п.,
- ансамбль пней – несложные нелинейные и т.п.

Несколько тонких моментов:
Как оценивать успешность восстановления признака? Лучше всего с помощью процедуры скользящего контроля (функцией cross_val_score в sklearn). Заметим, что мы можем использовать все имеющиеся данные, даже неразмеченные (для анализа зависимостей признаков целевые метки не важны). На практике для скорости часто используется случайное разбиение на две подвыборки: обучение и контроль в новой задаче.
Какие метрики качества использовать? Для «непрерывных» признаков лучше использовать RMSE. Но следует помнить, что изначально все признаки даны в разном масштабе, поэтому лучше их предварительно отнормировать (с винсоризацией), чтобы сравнивать «какой лучше восстановился». Для категориальных признаков иногда чуть сложнее найти адекватную метрику качества. Как правило, используется AUC ROC (для задачи с несколькими классами, если в признаке много категорий).
Как настраивать модель? Например, если я использую ансамбли над деревьями, то у меня есть некоторый проверенный набор параметров. Все параметры фиксированы, кроме числа деревьев – это число я варьирую и максимальное значение метрики качества на контроле по всем деревьям считаю оценкой «качества восстановления признака».
Анализ природы артефактов
В реальных данных много артефактов: пропусков, аномальных значений и т.п. Очень часто необходимо уметь определять их природу: не зависит ли их присутствие от значений признаков.
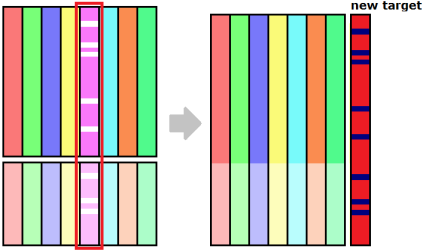
На рис. показана схема действий в этом случае. Выбираем признак, например, с пропусками. Удаляем его из таблицы, а целевым признаком назначаем характеристический признак наличия пропуска (=1 если пропуск есть на объекте, =0 если нет). Если новую задачу удаётся хорошо решить, то пропуски определяются значениями других признаков, по важностям можно определить каких именно.
Если в новой задаче таблицу данных целиком составить из характеристических признаков пропусков во всех признаках, то можно автоматически определить, зависит ли пропуск от факта наличия пропусков в других признаках.
Такие же приёмы можно использовать для поиска утечек (leakage) в соревновательном анализе данных. Например, в данные добавляют признак «номер строки», чтобы определить, зависит ли целевой признак от порядка объектов. Аналогично можно, наоборот, номер строки сделать целевым признаком – восстанавливается ли он по значениям других.
На практике я применял подобный приём при анализе показаний приборов. Сложное оборудование часто даёт сбои, поэтому показания разных датчиков в течение некоторых периодов могут быть некорректными. Если сделать модель восстановления показания и посмотреть, как меняется качество восстановления во времени, то можно определить периоды времени, в течение которых конкретным приборам нельзя верить.
Восстановление пропусков
Пусть в каком-то признаке есть пропущенные значения. Обычно их заполняют чем-то легко вычислимым, например средним значением или «числовым кодом» типа -999. А можно задаться целью – заполнить их тем, что наиболее подходит для заполнения.

Выберем признак с пропусками, назначим его целевым. В обучение пойдёт часть выборки, для которого его значение известно. После обучения модель запустим на остальной части и узнаем пропущенные значения.
Естественно, такую модель нужно хорошо отладить на скользящем контроле. Здесь также можно использовать неразмеченные данные. Если пропусков много, то можно выполнять итеративную процедуру: несколько раз пройти по всем признакам, для каждого признака восстановить пропущенные значения. Это позволит точнее восстанавливать пропуски: на базе других восстановленных пропусков. Переобучение в контексте исходно решаемой задачи здесь не так опасно, поскольку мы не используем значения целевого признака.
Если хорошо подумать, то проблема восстановления пропусков – самая общая проблема машинного обучения! Ведь решение исходной задачи – тоже восстановление пропусков, мы знаем значения целевого на обучении, но не знаем на тесте (т.е. они там пропущены).
Совпадение распределений обучения и контроля
Модель, обученную на определённой выборке, разумно применять на новых данных, если эти данные похожи на обучающую выборку. Проверить это можно простым способом: давайте сделаем бинарный целевой признак, который равен 1 на объектах теста и 0 – на объектах обучения, см. рис.

Если такую задачу удастся хорошо решить (а бывали случаи, когда на банковских данных клиентов начала и конца года, внешне довольно похожих, AUC ROC достигал 0.9), то значит обучение и тест не похожи. Посмотрев на важности признаков, можно понять почему…
Обычно этот приём используют в соревновательном анализе данных для подбора части обучающей выборки, которая похожа на тест. Если получить OOB-ответы модели (например, с помощью функции cross_val_predict), то из объектов обучения, у которых большая вероятность принадлежности тесту с точки зрения построенной модели, можно составить «похожую на тест подвыборку».
Все описанные выше приёмы кажутся очень эффективными для использования на практике, но есть множество нюансов… Почитайте, например, эту историю – использовать Adversarial Validation здесь не получилось и это нормально! Получается в одном случае из десяти! При решении бизнес-задач подобные приёмы ещё и сомнительны. В задачах, где новые данные не похожи на старые, следующие новые тоже будут не похожи. Если данные так часто меняются, нужны принципиально другие приёмы для синтеза стабильных моделей, чем постоянный подбор обучения.
Кластеризация признаков
Известно, что в задачах с дисбалансом классов при контроле качества следует следить, чтобы в обучении и тесте было одинаковое распределение объектов по классам. Есть даже специальные функции для организации такого контроля. А что делать в задачах регрессии? Например, есть немного аномально больших значений: разумно требовать, чтобы они попали в обучение и валидацию при скользящем контроле. Можно разбить значения целевого признака на группы «большие», «средние» и «маленькие» и применить упомянутую функцию. Тогда распределение объектов по этим группам будет сохранено. Более умно: сделать кластеризацию (вместо ручного разбиения).
Если Вы вдруг прочитали до конца, но не всё поняли — Вам подарок. Это пост сделан также и в виде обучающего ролика. Можете его посмотреть (признаюсь, что слайды сделаны наспех, не совсем продуман текст и много слов-паразитов, но лучше, чем ничего). Комментарии и замечания приветствуются! Стоит ли выпускать подобные ролики?

Отличный пост. В одном месте собраны техники и «фишки», которые нужно по форумам Kaggle выискивать. Спасибо!
Пожалуйста, пользуйтесь! Чем больше полезной информации, тем лучше;)
Самое интересное, что я про эти приёмы рассказывал ещё на своих курсах в МГУ до 2012 года (до активной работы Кэгловского форума), но тогда мало кому они казались интересными…
Так произошло потому что в те времена информацию по ML можно было найти только в ВУЗЕ. для желающих научиться — найти что-то было нереально 😦
Подскажите пожалуйста почему видео под замком, можете дать ссылки на другие видео или открыть подписчикам. У Вас один из самых полезных ресурсов на русском по ML.
Видео в режиме «доступ по ссылке». Его можно спокойно просматривать с этой страницы, но оно не отображается в моём ютуб-канале. Это эксперимент — я жду отзывов и смотрю, скольким людям оно понравится, сколько его посмотрят и какие будут замечания, чтобы решить, стоит ли делать подобные ролики. В принципе, в моих планах сделать их практически по всем темам ML…
Александр Геннадьевич, а можно поподробнее для отставших от сленга: что есть ансамбль пней? В голову приходит только аналогия с адски короткими деревьями (влоть до 1 листа)
Пень — дерево глубины 1, т.е. сравниваем признак с порогом, если выполнено — одна метка, не выполнено — другая.
Дополнение: в англоязычной литературе пень в таком контексте — это (decision) stump (https://en.wikipedia.org/wiki/Decision_stump).
А подскажите пожалуйста насколько помогает применение принципов adversarial validation след. образом:
1. Найти с помощью adversarial validation наиболее важные признаки, которые разделяют train & test
2. Обучить основной алгоритм без использования этих признаков.
Идея в том, что если эти признаки по другому ведут себя на тесте, то они могут в основной модели как улучшить, так и ухудшить результат — то есть делают результат более нестабильным.
Ну и в целом интересны идеи что делать, когда распределения train & test по какой-то причине разошлись, но модель делать всё равно надо.
Теоретически так и надо делать. Практически — в большинстве реальных кейсов такая практика сильно подводит. Если подумать, то это может быть связано с тем, что распределение целевого признака тоже смещается, а этот приём на него не влияет. Один из выходов — искать инвариантные признаки. Скажем несколько признаков могут «смещаться» в тесте, а их попарные отношения нет…
Спасибо за пост. Интересен тем, что более-менее упорядочено показаны некоторые эмпирические подходы, про такие в учебниках не прочитаешь (или я просто про такие не знаю). Конечно же, такой материал очень полезен тем, кто нацелен на практическую работу, в которой результативность преобладает над академической строгостью подхода.
Из пожеланий: добавить хоть сколько-нибудь формального описания на языке математике для снижения неоднозначности в восприятии словесного описания. В некоторые места я вчитывался по два раза, чтобы перевести это в формальную систему в своей голове. Может просто не был настроен на материал. )
Из больших пожеланий: издать книгу такой направленности, лучше на английском для максимального покрытия потенциальной аудитории. Я сейчас читаю The Data Science Design Manual by Steven S. Skiena. Известный автор, как мне думается, попытался достичь похожей цели, но книга, к сожалению, получилась не столь глубокая, как хотелось бы. Возможно, вы могли бы написать отличное дополнение к вышеуказанной книге.
А это потому, мне кажется, что Стивен Скиена и не является специалистом по машинному обучению.
Спасибо за столь ценную информацию!
По мне так подобные ролики выпускать очень стоит! В дополнение к статье они бесценны.
Круто, что сделали еще и видео слайды с объяснением! Думаю, многим так удобнее понимать смысл.
Спасибо!
В статье вы пишите:
«Если данные так часто меняются, нужны принципиально другие приёмы для синтеза стабильных моделей, чем постоянный подбор обучения»
А в видео говорите:
«Много каких способов можно дать»
А можно поподробнее о приёмах для синтеза стабильных моделей, менее чувствительных к смене распределения? Неоднократно возникало в работе. И, полагаю, не у меня одного.
Их много, потому что задача это ДНК (дано — найти — критерий), а решение это алгоритм + ответ.
Каждую из этих компонент можно заточить на стабильность….
Д) Можно перейти к стабильным данным, придумать инвариантные признаки, которые уже слабо меняются (например, в банковской задаче доход пронормировать на средний доход текущих клиентов)
Н) Пересмотреть, что будем называть ответом алгоритма.Например, алгоритм может очень нестабильно предсказывать цену акции, но стабильно качественно определять будет она расти или падать.
К) Придумать, как изменить функцию ошибки, чтобы алгоритм показывал стабильность. Если признаков много, они примерно одинаково хорошие, но есть часть нестабильных, то простая L2-регуляризация может помочь.
A) алгоритм — можно просто использовать более стабильные модели. Пример в DL — берём уже обученную модель и лишь немного дотюниваем на наши данные, каждое дотюнивание на новые данные делаем с регуляризацией по норме разности исходных весов и новых, чтобы новые данные не слишком меняли модель.
Спасибо за интересный пост!
Хотел уточнить у вас это место — «а бывали случаи, когда на банковских данных клиентов начала и конца года, внешне довольно похожих, AUC ROC достигал 0.9».
Как лучше решать подобную проблему?
Что делать если есть признак(или группа признаков), который аномален в первой половине года и стабилизируется к концу(как раз в тесте), но отбросить его нельзя тк. он достаточно важен? И так же, по понятным причинам, не хочется выбрасывать пол года данных.
Да, бывали. Не помню точно сколько, но близко к 0.9 было. Не помню точно причин: иногда они забавные. Например, в начале года выгрузка была в системе старой версии, а в конце — в новой. И отсутствие данных по-разному кодировалось: NaN и 0. Если не допускать таких искуственных различий, то AUC всё равно может быть довольно высоким.
Как решать — смотрите мои ответы на предыдущие комментарии.
Я уже как раз посмотрел. Вы говорите, что нужно сделать признак инвариантным, но что если есть такие, которые меняются в зависимости от целевого?
Например, вероятность дефолта оценённая по определённой группе признаков — вероятности меняются в течении года в зависимости от работы основной скоринговой модели(модель становится лучше и к нам начинают приходить более надежные клиенты). Что можно сделать в такой ситуации? Сможет ли фича вида отклонения от медианы/среднего за последние n дней/клиентов помочь в этой проблеме?
[…] Подмена задачи в ML (2408) […]
привет!
очень полезная статья.
спасибо за ваш блог, одно время жалел, что не пошел к вам в магу.
Александр, вы не думали сделать практический курс (видео уроки, ноутбуки) или целиком курс по МЛ как сделали, например, ребята из ODS? только более подробный, чем у них, с учетом вашего опыта и наработок, ВМКшного курса. как правило,практическая часть — это как раз то, чего не хватает большинству существующих курсов. она либо очень поверхностная — миллионы статей от индусов на медиуме — , либо очень сложная и при этом не подробная — типа Advanced Machine Learning на Cursera. и запустить все это на Ютубе и гит-репозиторием или, например, на той же курсере, как делала Вышка.
Здравствуйте! Думал, но пока на полноценный курс нет времени… тут на блог не всегда хватает:)
«Известно, что в задачах с дисбалансом классов при контроле качества следует следить, чтобы в обучении и тесте было одинаковое распределение объектов по классам.»
В процессе решения задачи да, но при этом я знаю, что при реальном использовании модели дисбаланс классов в наборе данных к которому будут применять алгоритм будет меняться от месяца к месяцу и по географическому признаку тоже, причем иногда очень сильно. А решать задачу нужно на месяц вперед. Столкнулся с такой проблемой при классификации отказов (дефектов). Возможно стоит наоборот как-то учитывать это при обучении. В результате (из-за ограниченности времени) использовали многократное случайное прореживание выборки и обучение ансамбля на эти прореженных выборках. Получилось, что алгоритм стал более устойчивым в плане точности к изменению дисбаланса классов. У меня вообще больше вопросов, чем ответов относительно проблемы «Learning from Imbalanced Data Sets», хотя я и прочитал (попробовал) много всего. Возможно вы что-то посоветуете.
То что Вы описали это не связано с самим дисбалансом, а с тем что распределения описаний объектов / целевого вектора меняется. Можно погуглить, например, «covariate shift», «target shift» и т.п.
Спасибо, буду изучать.
Для полноты картины добавлю, что идеи «Естественно, такую модель нужно хорошо отладить на скользящем контроле. Здесь также можно использовать неразмеченные данные. Если пропусков много, то можно выполнять итеративную процедуру: несколько раз пройти по всем признакам, для каждого признака восстановить пропущенные значения. Это позволит точнее восстанавливать пропуски: на базе других восстановленных пропусков.» уже реализованы в эскалёрне: https://scikit-learn.org/stable/modules/generated/sklearn.impute.IterativeImputer.html
Тот факт, что это стандартный трансформер, позволяет использовать его в конвейере и не переживать об утечках таргета. Ещё из интересного там возможность указать число «ближайших» фичей, по которому будет идти восстановление пропусков (для снижения вычислительнйо нагрузки), жёсткие лимиты на восстановленные значения, добавление флага пропущенного значения несмотря на то, что оно было восстановлено.